Chapter 1 Welcome to R
"I believe that R currently represents the best medium for quality software in support of data analysis."
- John Chambers, Developer of S
"R is a real demonstration of the power of collaboration, and I don’t think you could construct something like this any other way."
- Ross Ihaka, original co-developer of R
1.1 What is R?
R is a computer language and an open source setting for statistics, data management, computation, and graphics. The outward mien of the R-environment is minimalistic, with few menu-driven interactive facilities (no menus exist for some implementations of R). This is in contrast to conventional statistical software consisting of black box, menu-dominated, often inflexible tools. The simplicity of R allows one to easily evaluate, edit, and build procedures for data analysis, and many other purposes.
1.2 R and Biology
I am a statistical ecologist, so this book was written with natural scientists, particularly biologists, in mind. R is useful to biologists for three major reasons. First, it provides access to a large number of cutting edge statistical, graphical, and organizational procedures, many of which have been designed specifically for biological research. Second, biological datasets, including those from genetic and spatiotemporal research can be extensive and complex. R can readily manage and analyze such data. Third, analysis of biological data often requires analytical and computational flexibility. R allows one to “get under the hood”, look at the code, and check to see what algorithms are doing. If, after examining an R-algorithm we are unsatisfied, we can generally modify its code or create new code to meet our specific needs.
1.3 Popularity of R
Because of its freeware status, the overall number of people using R
is difficult to determine. Nonetheless, the R-consortium website estimates that there are currently more than two million active R users. The r4stats
website houses up-to-date
surveys concerning the popularity of analytical software. These surveys
(accessed 10/23/2024) indicate that R is often preferred among
data scientists for big data projects and data mining. R is also one
of the most frequently cited statistical environments in scholarly
articles, one of the most frequently used languages on the
GitHub repository, and one of the most frequently
discussed languages on Stack Overflow. In
2024 the R language was ranked 20th in the
world by the
Institute of Electrical and Electronics Engineers
(IEEE), and was recently (10/23/2024) ranked 6th by the PopularitY of Programming Language (PYPL) Index, which uses the search string 'X tutorial', as an indicator of future language usage. Further, in a 2017 survey, based on Stack Overflow queries, R was the “least disliked"
programming language.
The growth and popularity of R can be partially tied to its relatively straightforward extendability via user generated functions and packages. This characteristic prompts a strong sense of community among R-users, along with a practical need for the perpetuation and upkeep of the R system. While trailing Python, there are currently over 20000 formally contributed R-packages at the Comprehensive R Archive Network (CRAN).
1.4 A Brief History
R was created in the early 1990s by Australian computational statisticians Ross Ihaka and Robert Gentleman (Fig 1.1) to address scope1 and memory use deficiencies in its primary progenitor language, S (Ihaka and Gentleman 1996). Ihaka and Gentleman used the name R both to acknowledge the influence of S (because r and s are juxtaposed in the alphabet), and to celebrate their own personal efforts (because R was the first letter of their first names).

Figure 1.1: Ross Ihaka (1954 - ) (L) and Robert Gentleman (1959 - ) (R), the co-creators of R.
At the insistence of Swiss statistician Martin Maechler (Fig 1.2l), Ihaka and Gentleman distributed the R source code in 1995 under the Free Software Foundation’s GNU general license (Ihaka 1998). Because of its relatively easy-to-learn language, R was quickly extended with code and packages developed by its users. The rapid growth of R gave rise to the need for a group to guide its progress. This led, in 1997, to the establishment of the R-development core team2, an international panel that modifies, troubleshoots, and manages source code (Fig 1.2).

Figure 1.2: A recent version of the R-core development team.
1.4.1 Development of the R Language
The R language is based on older languages, particularly S, developed at Bell Laboratories (Richard Becker and Chambers 1978; RA Becker and Chambers 1981; Richard Becker, Chambers, and Wilks 1988), and Lisp3 (McCarthy 1978) and Scheme, a dialect of Lisp (Sussman and Steele Jr 1998; Steele 1978), which were developed at the MIT artificial intelligence laboratory in the late 1970s (Fig 1.3).

Figure 1.3: John McCarthy (1927-2011), creator of the Lisp language, and the first to coin the term “artifical intelligence”, working at the MIT AI laboratory. Lisp was the first language that allowed information to be stored as distinct objects, rather than simply collections of numbers.
In the appendix to his book Software for Data Analysis, John M. Chambers (Fig 1.2b), a primary developer of S, recounts the unique evolution and goals of S from its inception in 1976 (Chambers 2008). Chambers notes that S was originally intended to be an analysis toolbox solely for the statistics research group at Bell Labs, consisting of roughly 20 people at the time. It was decided that S (initially known as “the system”) would have fundamental extensibility4, reflecting the Bell Labs’ philosophy that “collaborations could actually enhance research” (Chambers 2008)5. The S language definition, and details concerning the fitting and application of S statistical models are given in Richard Becker, Chambers, and Wilks (1988) and Chambers and Hastie (1992), respectively6.
S was designed to diminish inner functional details of its underlying Fortran7 algorithms while making important higher-level processes more readily accessible and interactive. The inspiration for these goals was the exploratory data analysis approach of John Tukey (Fig 1.4), who was a contemporary of Chambers and other S developers8 at Bell Labs (Chambers 2020). In a 1965 Bell Labs memo (15 years before the release of S) Tukey noted that modern statistician found themselves in a “peaceful collision of computing and data analysis” (Chambers 1999).
![John Tukey (1915-2000), widely known for achievements in mathematical statistics, including the fast Fourier transform [@cooley1965], tools in exploratory data analysis, including the boxplot [@tukey1977], and computer science where he coined the term *bit*, as a unit of binary infomration and memory [@shannon1948].](figs1/Tukey.jpg)
Figure 1.4: John Tukey (1915-2000), widely known for achievements in mathematical statistics, including the fast Fourier transform (Cooley and Tukey 1965), tools in exploratory data analysis, including the boxplot (Tukey et al. 1977), and computer science where he coined the term bit, as a unit of binary infomration and memory (Shannon 1948).
An adherence of S to exploratory data analysis was evident in its high-quality, interactive graphics devices, and easily-accessible function documentation. The initial programmatic objectives of S are apparent in an early design sketch that describes an outer ‘user interface’ layer to core Fortran algorithms that ultimately produces an S object (Fig 1.5). The underlying philosophical principles and programmatic foundations of S have strongly affected and guided the development of R (Chambers 2020).
![First designs for the **S** statistical system, *circa* 1976 [@chambers2008]. Written in the lower lefthand corner is the important note: ‘Names are meaningful to algorithm, not necessarily to language.’](figs1/Ssketch.png)
Figure 1.5: First designs for the S statistical system, circa 1976 (Chambers 2008). Written in the lower lefthand corner is the important note: ‘Names are meaningful to algorithm, not necessarily to language.’
S evolved alongside the Unix operating system (also developed at Bell Labs) which currently underlies Macintosh and Linux (free-Unix) operating systems9. An early inception S was written for Unix, allowing S to be portable to any machine using Unix. Both S and Unix were quickly commercially licensed by AT&T for university and third party retailers. The academic licensing and distribution of S attracted a large number user groups in 1980s. However, the lack of a clear open source strategy caused many early users to switch from S to R in the 1990s. S was purchased by Insightful\(^{\circledR}\) software 2004 to run the commercial software S-Plus\(^{\circledR}\). In 2021 S-Plus\(^{\circledR}\) morphed to include TIBCO connected intelligence software, with some R open source applications.
1.4.1.1 R is Born
The original Scheme-inspired R interpreter consisted of roughly 1000 lines of C10 code which was driven by a command line interface that used a syntax corresponding to S, resulting in “a free implementation of something ‘close to’ version 3 of the S language (S3)” (Ihaka 1998). The R and S languages remain very similar, and code written in S can generally be run unaltered in R. The method of function implementation in R, however, remains more similar to Scheme. The official language definition of the current version of R can be found at the CRAN website, along with other sources of complementary information.
1.4.1.2 Differences of R and S
S3 and the initial release of R differed in two important ways (Ihaka and Gentleman 1996)11. First, the R-environment was given a fixed amount of memory at start up. This was in contrast to S-engines which adjusted available memory to session needs. Among other things, this difference meant more available pre-reserved computer memory, and fewer virtual pagination12 problems in R (Ihaka and Gentleman 1996). It also made R faster than S for many applications (Hornik and R Core Team 2023). Second, R variable locations are lexically scoped. In computer science, variables are storage areas with identifiers, and scope defines the context in which a variable name is recognized. So-called global variables are accessible in every scope (for instance, both inside and outside functions). In contrast, local variables may only exist only within particular localized scopes. Formal parameters defined in R functions, including arguments, are (generally) local variables, whereas variables created outside of functions are global variables. In contrast to S, lexical scoping allowed functions in R access to variables that were in effect when the function was defined in a session. The characteristics of R functions and details concerning lexical scoping are further addressed in Ch 8.
1.4.2 Recent Developments
According to Thieme (2018), a growing component of the R culture includes individuals who are “Less interested in the mechanics of R than in what R allowed them to do.” This group, which often includes individuals from non-R backgrounds (but with expertise in other languages C, Java, HTML, etc.), and those “who may have little interest in becoming computer scientists”, has been championed by Hadley Wickham (Fig 1.6), creator of the important ggplot2 and dplyr R packages, and author of many useful books on R programming. A larger collection of packages supported by Wickham is referred to as the tidyverse (Wickham et al. 2019) (see Ch 5).
Figure 1.6: Hadley Wickham (1979 - ) chief scientist at Rstudio.
1.4.3 The Future of R
It is apparent that R can be tied (particularly via linkages with Fortran and Lisp) to early examples of software engineering, and (via John Tukey and others) to foundational figures in data science. The future of R will be determined by the formal and informal community of users who have donated years of their lives to its development without monetary compensation. Importantly, the continued growth of R will require adaptation to the changing demography of R-users. Like most software endeavors, R has been male dominated (Fig 1.2). However, this has been changing rapidly. As an example, the R Ladies group, founded in 2012 by Gabriela de Queiroz (Fig 1.7), currently (8/6/2024) has 225 chapters in 65 countries, and more than 39,000 members worldwide.

Figure 1.7: Gabriela de Queiroz, chief data scientist at IBM.
1.5 Copyrights and Licenses
R is intentionally open-source and free. Thus, there are no
warranties on its environment or packages. As its copyright framework R uses the GNU (a recursive acronym for GNU is not Unix) General Public License (GPL). This allows users to share and change R and its functions. The associated legalese can read after typing RShowDoc("COPYING") in the R-console. Because its functions can be legally (and easily) recycled and altered we should always give credit to developers, package maintainers, or whomever wrote the R functions or code we are using.
1.6 R and Reliability
The lack of an R warranty has frightened away some scientists. But be assured, with few exceptions, R works as well or better than “top of the line” analytical commercial software. Indeed, statistical software giants SAS\(^{\circledR}\) and SPSS\(^{\circledR}\) have made R applications accessible from within their products (Fox 2009), and R processes and files can be shared directly with Microsoft Excel\(^{\circledR}\) and other proprietary software. For specialized or advanced statistical techniques R often outperforms other alternatives because of its diverse array of continually updated applications.
The computing engines and packages that come with a conventional R download (see Section 3.5) meet or exceed U.S. federal analytical standards for clinical trial research (Schwartz et al. 2008). In addition, core algorithms used in R are based on seminal and well-trusted functions. For instance, R random number generators include some of the most venerated and thoroughly tested functions in computer history (Chambers 2008). Similarly, the Linear Algebra PACKage (LAPACK) algorithms (Anderson et al. 1999), used by R, are among the world’s most stable and best-tested software.
1.7 Installation
To install R, first go to the website (http://www.r-project.org/). On this page specify which platform you are using (Fig 1.8, step 1). R can currently be used on Unix/Linux, Windows and Mac operating systems. Once an operating system has been selected, one can click on the “base” link to download the precompiled base binaries if R currently exists on your computer. If R has not been previously installed on your computer click on “Install R for the first time” (Fig 1.8, step 2). You will delivered to a window containing a link to download the most recent version of R by clicking on the “Download” link (Fig 1.8, step 3). Two versions of R are generally released each year, one in April and one in October. Archived, older versions of R and R packages are also available from CRAN.
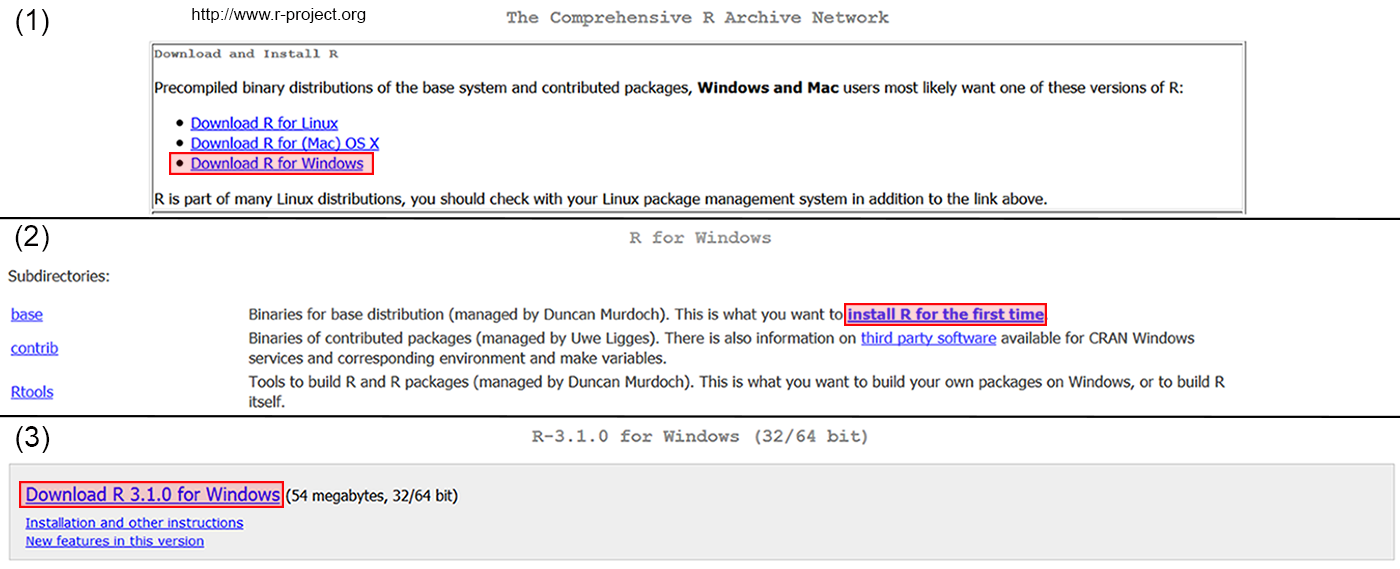
Figure 1.8: Method for installing R for Windows for the first time.
Exercises
- The following questions concern the history and general characteristics of R.
- Who were the creators of R?
- What are some major developmental events in the history of R?
- What languages is R derived from and/or most similar to?
- What features distinguish R from other languages and statistical software?
- What are the three operating systems R works with?
- Briefly consider R in the context of major historical events in computer software and artificial intelligence.
References
In computer science, scope refers to the degree of binding between an identifier of an entity (e.g., an object name) and the entity itself (e.g., an object).↩︎
The first R-core consisted of: Douglas Bates, Peter Dalgaard, Robert Gentleman, Kurt Hornik, Ross Ihaka, Friedrich Leisch, Thomas Lumley, Martin Mächler, Paul Murrell, Heiner Schwarte, and Luke Tierney. Several of these individuals remain in the current R-core (Fig 1.2).↩︎
Lisp, an abbreviation of “LISt Processor”, is the second-oldest (after Fortran) high-level programming language still in common use.↩︎
In software engineering, extensibility is a design principle that provides for future growth. This allows developers to easily expand the software capabilities.↩︎
Notably, although S was originally designed to support statistical analysis, Chambers (2020) asserted that its actual usage at Bell Labs would be viewed today as data science defined as “techniques and their application to derive and communicate scientifically valid inferences and predictions based on relevant data.”↩︎
Richard Becker, Chambers, and Wilks (1988) described the third version of S, S3. Chambers and Hastie (1992) introduced formula-notation using the
~operator, dataframe objects, and modifications to object methods and classes (Wikipedia 2024). These publications were often referred to as the blue book and the white book by S-users, due to color of their covers.↩︎Fortran (FORmula TRANslator) is a computer language developed by IBM in the 1950s for science and engineering applications. Remarkably, it remains useful for many applications, including speeding up slow looping routines in interpreted languages like R.↩︎
Other important contributors to S included Rick Becker, Trevor Hastie, William Cleveland, and Allan Wilks of Bell Labs.↩︎
Unix itself was originally written in assembly language (a low-level programming language with a very strong correspondence between language instructions and machine/operating system instructions). Unix was later re-written in C.↩︎
C is a portable, general purpose language, initially developed by Dennis Ritchie (Kernighan and Ritchie 2002). C, in turn, evolved from the language B, created by Ken Thompson (Thompson 1972), which, in turn, was inspired by work on early operating system called Multics (Corbató and Vyssotsky 1965)↩︎
For additional demonstrations of the technical differences of R and S see (Hornik and R Core Team 2023)↩︎
Virtual pagination is a memory management scheme that allows a computer to store and retrieve data from secondary storage for use in main memory.↩︎